
الگوریتم یادگیری تقویتی Reinforcement Learning
 توسط مریم گوهرزاد
توسط مریم گوهرزاد- هوش مصنوعی
- آوریل 27, 2025
- 1 دقیقه زمان خواندن
- 599 بازدید
این مقاله به بررسی کاربرد الگوریتم یادگیری تقویتی در بازار ارزهای دیجیتال میپردازد و تحلیل میکند که چگونه این الگوریتم میتواند به بهبود پیشبینی قیمتها و اتخاذ تصمیمات بهینه در ترید کمک کند. مزایا، چالشها و روشهای پیادهسازی این الگوریتم در شرایط نوسانی بازار بررسی میشود.
الگوریتم یادگیری تقویتی (Reinforcement Learning) یکی از شاخههای پیشرفته یادگیری ماشین است که بهطور خاص بر روی یادگیری از طریق تعامل با محیط تمرکز دارد. در این روش، یک عامل (Agent) با اتخاذ اقداماتی در یک محیط (Environment) سعی میکند تا بازخوردهایی (پاداشها) دریافت کند و در نتیجه رفتار خود را بهبود بخشد. برخلاف روشهای یادگیری نظارتشده، که نیازمند دادههای دارای برچسب هستند، یادگیری تقویتی به عامل اجازه میدهد تا از تجربیات خود یاد بگیرد و به تدریج استراتژی های بهینه را برای دستیابی به اهداف مشخص توسعه دهد.
یادگیری تقویتی در زمینههای مختلفی از جمله بازیهای ویدیویی، رباتیک، کنترل سیستمها و حتی بهینهسازی فرآیندها کاربرد دارد. با پیشرفتهای اخیر در الگوریتمها و تکنیکهای مرتبط، این حوزه به یکی از موضوعات جذاب و پرطرفدار در علم داده و هوش مصنوعی تبدیل شده است. در این مقاله، به بررسی اصول اولیه، تکنیکها و کاربردهای الگوریتم یادگیری تقویتی خواهیم پرداخت.
Table of contents [Show]
تفاوت یادگیری نظارتشده (Supervised Learning) و یادگیری غیرنظارتشده (Unsupervised Learning)
یادگیری ماشین به دو دسته اصلی تقسیم میشود: یادگیری نظارتشده (Supervised Learning) و یادگیری غیرنظارتشده (Unsupervised Learning). این دو روش بهطور بنیادین در نحوه استفاده از دادهها و نوع نتایج مورد انتظار تفاوت دارند.
یادگیری نظارت شده (Supervised Learning)
یادگیری نظارتشده یک روش در یادگیری ماشین است که در آن مدل با استفاده از دادههای ورودی و خروجی مشخص آموزش داده میشود. این دادهها شامل ویژگیها (Features) و برچسبها (Labels) هستند. هدف این روش پیشبینی یا طبقهبندی دادههای جدید بر اساس الگوهایی است که از دادههای آموزشی آموخته شدهاند. بهعنوان مثال، در یک مدل پیشبینی قیمت خانه، ویژگیها میتوانند شامل متراژ، تعداد اتاقها و موقعیت باشند، در حالی که برچسب، قیمت واقعی خانه است. این روش در کاربردهایی مانند پیشبینی قیمتها، تشخیص ایمیلهای اسپم و طبقهبندی تصاویر بسیار موثر است.
یادگیری غیرنظارتشده (Unsupervised Learning)
یادگیری غیرنظارتشده به روشی در یادگیری ماشین اشاره دارد که در آن مدل تنها با دادههای ورودی کار میکند و هیچ برچسبی برای خروجی وجود ندارد. هدف این روش کشف الگوها و ساختارهای نهفته در دادهها است. در این حالت، مدل سعی میکند الگوهای مشابه را شناسایی کرده و دادهها را به خوشههایی تقسیم کند. بهعنوان مثال، در خوشهبندی مشتریان، مدل میتواند گروههایی از مشتریان با رفتار مشابه را شناسایی کند بدون اینکه برچسبی برای هر مشتری وجود داشته باشد. این روش در کاربردهایی نظیر تحلیل بازار و کاهش ابعاد دادهها با استفاده از تکنیکهایی مانند PCA بسیار مفید است.
یادگیری تقویتی (Reinforcement Learning) چیست؟
حالا میرسیم به یادگیری تقویتی یا Reinforcement Learning (RL) که یکی از روشهای یادگیری ماشین است. در RL، سیستم بهطور مستقل یاد میگیرد که چه اقداماتی باید انجام دهد تا بیشترین پاداش (Reward) را در یک محیط خاص بهدست آورد. تفاوت اصلی آن با یادگیری نظارت شده در این است که در این روش، مدل نیازی به برچسبهای دادهای ندارد، بلکه خودش از طریق تعامل با محیط یاد میگیرد.
در اینجا چند مفهوم کلیدی در RL داریم که باید با آنها آشنا شویم:
- Agent (عامل): موجودی که در محیط قرار دارد و میخواهد تصمیمات بهینه بگیرد.
- Environment (محیط): جایی که عامل در آن قرار دارد و باید تصمیم بگیرد.
- Action (اقدام): کارهایی که عامل میتواند انجام دهد.
- State (وضعیت): شرایط یا موقعیتهای مختلفی که عامل در آنها قرار میگیرد.
- Reward (پاداش): بازخوردی که عامل بعد از انجام هر اقدام از محیط دریافت میکند. این پاداش میتواند مثبت یا منفی باشد.
- Policy (سیاست): استراتژی یا نقشهای که عامل برای تصمیمگیری در شرایط مختلف دنبال میکند.
اساس کار الگوریتم یادگیری تقویتی چیست؟
در یادگیری تقویتی (Reinforcement Learning)، عامل (Agent) با انجام اقدامات مختلف در یک محیط (Environment) وارد وضعیتهای متنوعی میشود و بعد از هر اقدام، بازخوردی بهصورت پاداش یا جریمه دریافت میکند. هدف اصلی این عامل یادگیری مجموعهای از اقدامات است که منجر به بیشترین پاداش ممکن شود.
بهعنوان یک مثال ساده، فرض کنید عامل در یک بازی شطرنج قرار دارد. این عامل باید هر حرکت را بهگونهای انتخاب کند که در نهایت به پیروزی برسد. هر بار که او حرکت موثری انجام میدهد، مانند گرفتن یک مهره از حریف، پاداش مثبت دریافت میکند. برعکس، اگر حرکتی نامناسب انجام دهد که منجر به از دست دادن مهره شود، پاداش منفی دریافت میکند. این بازخوردها به عامل کمک میکنند تا استراتژیهای بهتری برای رسیدن به هدف نهایی خود توسعه دهد.
فرایند یادگیری در RL (الگوریتم یادگیری تقویتی)
فرایند یادگیری در RL معمولاً شامل مراحل زیر است:
- انتخاب اقدام (Action Selection): عامل یک اقدام را بر اساس سیاست خود انتخاب میکند.
- تعامل با محیط (Interaction with the Environment): عامل اقدام خود را انجام میدهد و محیط به آن پاسخ میدهد (یعنی وضعیت جدیدی ایجاد میشود).
- دریافت پاداش (Reward Feedback): بعد از انجام اقدام، عامل یک پاداش (یا جریمه) دریافت میکند.
- بهروزرسانی سیاست (Policy Update): عامل بر اساس پاداشی که دریافت کرده، سیاست خود را بهروزرسانی میکند تا در آینده اقدامات بهتری انجام دهد.
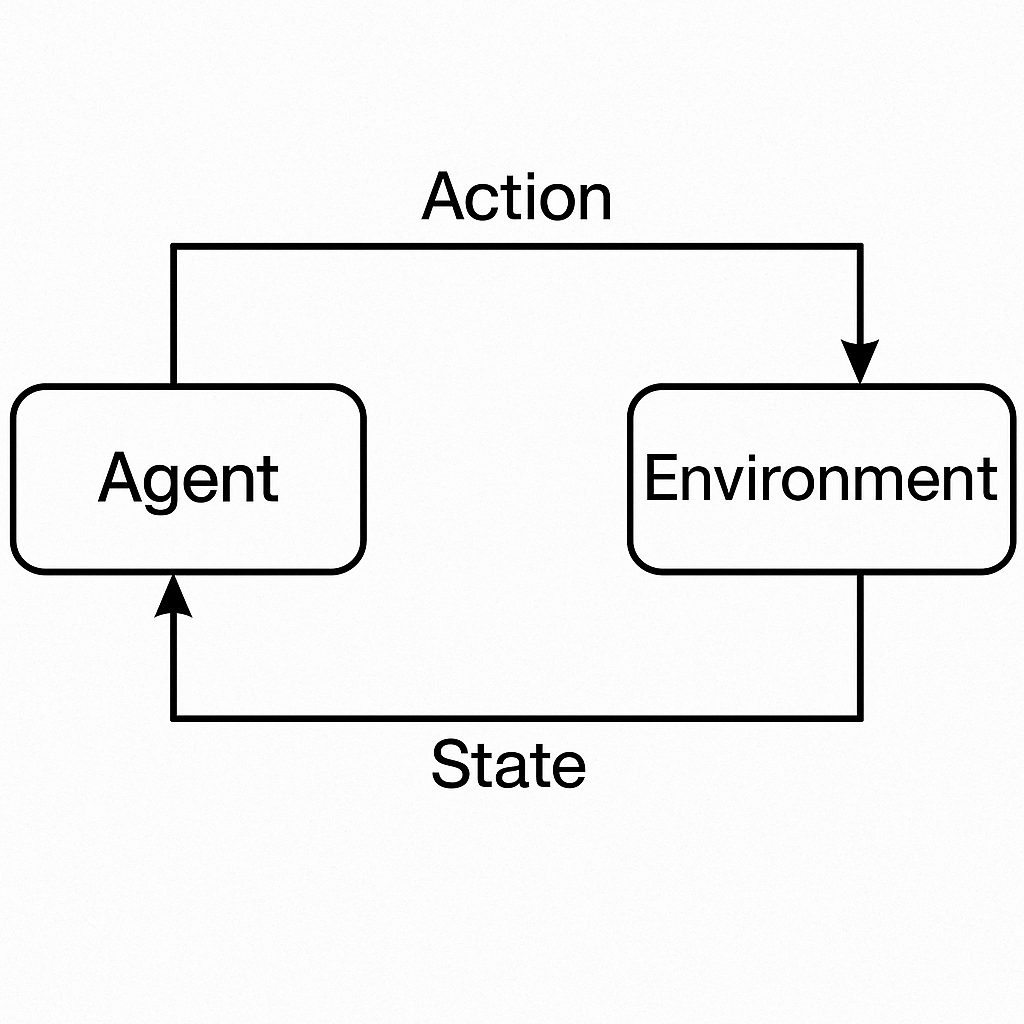
این تصویر فرآیند یادگیری تقویتی را نشان میدهد. در این فرایند، عامل (Agent) با انجام اقدامات (Action) در محیط (Environment) وارد وضعیتها (State) میشود و پاداش (Reward) دریافت میکند. این تعاملها به عامل کمک میکنند تا سیاست بهینه را برای دستیابی به بیشترین پاداش در بلندمدت یاد بگیرد.
مثال کاربردی: بازی مار (Snake Game)
فرض کنید یک عامل در حال بازی کردن مار است. هدف او این است که مار را به گونهای حرکت دهد که طول آن زیاد شود بدون اینکه به دیوارها یا خود مار برخورد کند.
- State: وضعیت مار، موقعیت غذا و دیوارها.
- Action: حرکت مار به سمت بالا، پایین، چپ یا راست.
- Reward: به ازای هر بار که مار غذا میخورد، پاداش مثبت دریافت میکند و اگر به دیوار یا خود برخورد کند، پاداش منفی میگیرد.
در این بازی، عامل باید یاد بگیرد که چگونه مار را حرکت دهد تا به غذا برسد و از برخورد با موانع اجتناب کند.
الگوریتمهای RL
در یادگیری تقویتی، الگوریتمهای مختلفی برای بهینهسازی سیاست عامل وجود دارند. دو تا از معروفترین این الگوریتمها عبارتند از:
- Q-Learning: این الگوریتم بهصورت مستقل از مدل محیط، یاد میگیرد که برای هر وضعیت و اقدام، چه پاداشی ممکن است دریافت شود.
- Deep Q-Networks (DQN): یک نسخه پیشرفته از Q-Learning است که از شبکههای عصبی برای بهبود دقت پیشبینیها استفاده میکند.
الگوریتم یادگیری تقویتی برای طراحی ربات ترید ارزهای دیجیتال
الگوریتم یادگیری تقویتی (Reinforcement Learning) میتواند در طراحی ربات ترید ارزهای دیجیتال مفید و کاربردی باشد. اما این که چقدر «قوی» باشد، بستگی به چگونگی طراحی و پیادهسازی آن دارد. در اینجا به برخی از مزایا و چالشهای استفاده از RL برای پیشبینی قیمت و ترید ارزهای دیجیتال اشاره میکنم.
مزایای استفاده از یادگیری تقویتی در ربات ترید ارزهای دیجیتال
- یادگیری خودکار و بهینهسازی تصمیمات:
- در یادگیری تقویتی، عامل (ربات) میتواند از تجربیات خود در بازار یاد بگیرد. به عبارت دیگر، عامل با آزمون و خطا بهترین استراتژی ترید را برای شرایط مختلف بازار پیدا میکند.
- در حالی که مدلهای پیشبینی سنتی معمولاً به دادههای گذشته وابستهاند، یادگیری تقویتی میتواند بهطور پویا و در زمان واقعی تصمیمگیری کند و خود را با تغییرات بازار تطبیق دهد.
- پاداشهای بلندمدت:
- یکی از ویژگیهای مهم یادگیری تقویتی این است که میتواند به جای تمرکز بر پاداشهای کوتاهمدت، استراتژیهایی را یاد بگیرد که بیشترین پاداشهای بلندمدت را ایجاد کنند. این ویژگی در بازارهای ناپایدار مانند ارزهای دیجیتال بسیار مفید است، زیرا میتواند به ربات کمک کند تا از تغییرات ناگهانی بازار بهرهبرداری کند.
- انعطافپذیری در محیطهای پیچیده:
- بازارهای ارز دیجیتال پیچیده و پویا هستند و یادگیری تقویتی این امکان را به ربات میدهد که در مواجهه با این پیچیدگیها، از دادههای لحظهای و شرایط جدید بهرهبرداری کند.
معایب استفاده از یادگیری تقویتی در ربات ترید ارزهای دیجیتال
- نیاز به دادههای زیاد و متنوع:
- یادگیری تقویتی نیازمند حجم زیادی از دادهها برای آموزش است. در بازارهای ارز دیجیتال، پیشبینی دقیق قیمتها میتواند چالشبرانگیز باشد زیرا دادههای بازار پیچیده و دارای نویز زیادی هستند. بنابراین، آموزش مدل برای RL میتواند زمانبر و پرهزینه باشد.
- آسیبپذیری نسبت به تغییرات بازار:
- یادگیری تقویتی بهطور کلی به تغییرات بازار حساس است. حتی مدلهای بسیار پیچیده میتوانند در شرایط خاص بازار شکست بخورند. در نتیجه، بهروزرسانی مداوم و نظارت دقیق بر عملکرد مدل بسیار مهم است.
- تخفیف و تاخیر در پاداشها:
- یکی از چالشهای استفاده از یادگیری تقویتی برای ترید ارزهای دیجیتال این است که ممکن است پاداشها با تأخیر دریافت شوند. در بازارهای سریع و نوسانی، این تأخیر میتواند منجر به تصمیمات اشتباه شود.
کاربرد در پیشبینی و تشخیص قیمت ارز دیجیتال
- استفاده از یادگیری تقویتی برای پیشبینی قیمت ارزهای دیجیتال میتواند در سناریوهای خاص مفید باشد. برای مثال، اگر مدل قادر به یادگیری و شبیهسازی الگوهای مختلف بازار و همچنین تاثیرات ناشی از اخبار و رویدادها باشد، میتواند بهطور مؤثری پیشبینیهایی برای نوسانات قیمت انجام دهد.
- الگوریتمهایی مانند Deep Q-Learning یا Proximal Policy Optimization (PPO) میتوانند برای یادگیری سیاستهای معاملاتی به کار گرفته شوند. این الگوریتمها میتوانند به طور خودکار پوزیشنهای خرید یا فروش را براساس وضعیت بازار انتخاب کنند.
نتیجهگیری:
در نهایت، یادگیری تقویتی بهعنوان یک روش قدرتمند در حوزه هوش مصنوعی، پتانسیل بالایی برای پیشبینی و تصمیمگیری در بازار ارزهای دیجیتال دارد، اما چالشهای خود را نیز دارد. موفقیت استفاده از آن بستگی به کیفیت دادهها، طراحی الگوریتم و مدیریت نوسانات بازار دارد. بنابراین، اگر بهدرستی طراحی و پیادهسازی شود، میتواند یک ابزار مؤثر در ترید ارزهای دیجیتال باشد، ولی نیاز به آزمون و بهینهسازی مداوم دارد.
مریم گوهرزاد
مدرس و بنیانگذار هلدینگ آرتا رسانه. برنامه نویس و محقق حوزه بلاکچین



