
نقشه راه یادگیری پایتون
 توسط مریم گوهرزاد
توسط مریم گوهرزاد- برنامه نویسی
- آوریل 27, 2025
- 5 دقیقه زمان خواندن
- 897 بازدید
نقشه راه کامل یادگیری پایتون، از مفاهیم پایه تا برنامهنویسی پیشرفته، شامل شیگرایی، ساختمان داده، فریمورکهای وب، اتوماسیون، تستنویسی و علم داده. مناسب برای مبتدیان تا برنامهنویسان حرفهای.
پایتون، به عنوان یکی از محبوبترین و پرکاربردترین زبانهای برنامهنویسی دنیا، به دلیل سادگی، انعطافپذیری و جامعهی بزرگ توسعه دهندگانش، گزینهای ایدهآل برای مبتدیان و حرفهایها است. از توسعه وب و تحلیل داده گرفته تا هوش مصنوعی و اتوماسیون، پایتون در حوزههای متنوعی کاربرد دارد. اما یادگیری این زبان قدرتمند میتواند برای تازهکاران چالشبرانگیز باشد، بهویژه اگر ندانند از کجا شروع کنند یا چگونه مسیر خود را ادامه دهند. در این مقاله، یک نقشهی راه جامع و ساختاریافته برای یادگیری پایتون ارائه میدهیم که شما را از مفاهیم پایه تا پروژههای پیشرفته هدایت میکند. هدف این است که با تمرکز بر یادگیری گامبهگام و تمرین عملی، بتوانید به تسلطی کاربردی و عمیق در پایتون دست یابید. البته شما که علاقه مند به آموزش برنامه نویسی هستید، توصیه می کنیمآموزش برنامه نویسی بلاکچین را هم در برنامه خود قرار دهید.
Table of contents [Show]
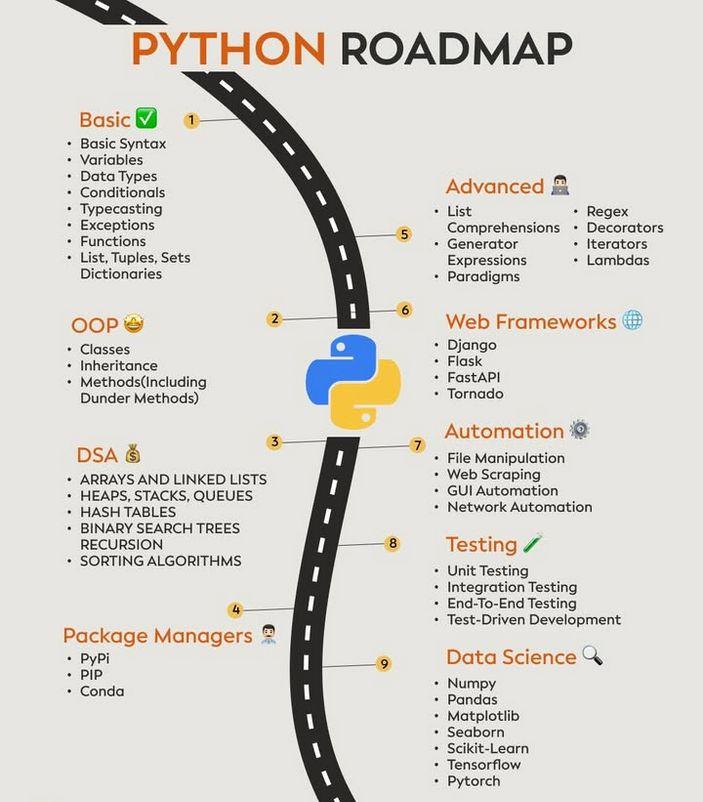
- 1 مباحث پایه (Basic)
- 2 برنامهنویسی شیگرا (OOP)
- 3 ساختمان داده و الگوریتمها (DSA) در پایتون
- 3. 1 تحلیل پیچیدگی (Time and Space Complexity)
- 3. 2 آرایهها و لیستهای پیوندی (Arrays & Linked Lists)
- 3. 3 پشتهها، صفها و هیپها (Stacks, Queues, Heaps)
- 3. 4 جدولهای هش (Hash Tables)
- 3. 5 درختهای جستجوی دودویی (Binary Search Trees - BST)
- 3. 6 گرافها (Graphs)
- 3. 7 بازگشت (Recursion)
- 3. 8 الگوریتمهای جستجو (Search Algorithms)
- 3. 9 الگوریتمهای مرتبسازی (Sorting Algorithms)
- 4 مدیریت پکیجها (Package Managers)
- 5 مباحث پیشرفته در پایتون
- 5. 1 ساختارهای فهرستی (List Comprehension)
- 5. 2 مولدها (Generators)
- 5. 3 عبارات شرطی و پویا
- 5. 4 پارادایمهای برنامهنویسی (Programming Paradigms)
- 5. 5 عبارات منظم (Regular Expressions - Regex)
- 5. 6 دکوراتورها (Decorators)
- 5. 7 تکرارکنندهها (Iterators)
- 5. 8 توابع لامبدا (Lambda Functions)
- 5. 9 همزمانی و موازیسازی (Concurrency and Parallelism)
- 5. 10 متاکلاسها (Metaclasses)
- 5. 11 بهینهسازی عملکرد
- 6 فریم ورک های پایتون
- 7 اتوماسیون و تستنویسی با پایتون
- 7. 1 کار با فایلها
- 7. 2 استخراج اطلاعات از وب (Web Scraping)
- 7. 3 اتوماسیون رابط کاربری (GUI Automation)
- 7. 4 اتوماسیون شبکه
- 7. 5 تستنویسی (Testing)
- 7. 6 تست واحد (Unit Testing)
- 7. 7 تست یکپارچه (Integration Testing)
- 7. 8 تست سرتاسری (End-to-End Testing)
- 7. 9 توسعه مبتنی بر تست (Test-Driven Development - TDD)
- 8 علم داده (Data Science)
مباحث پایه (Basic)
- نحوه نوشتار پایه (Syntax): قواعد بنیادین که ساختار نگارش کد در زبان پایتون را تعیین میکنند. به عنوان مثال، استفاده از تورفتگی (Indentation) به جای کروشهها ({}) برای تعریف بلوکهای کد الزامی است. رعایت این قواعد، کد را قابل اجرا و خوانا میسازد.
- متغیرها (Variables): متغیرها برای ذخیرهسازی دادهها در حافظه به کار میروند و به مثابه برچسبهایی هستند که به مقادیر خاصی ارجاع میدهند. در پایتون، نیازی به تعیین نوع متغیر به صورت صریح نیست، زیرا زبان به طور خودکار نوع داده را شناسایی میکند.
- انواع داده (Data Types): هر داده در برنامهنویسی دارای نوع مشخصی است، مانند اعداد، رشتههای متنی یا مقادیر منطقی. آگاهی از انواع دادهها به مدیریت صحیح و کارآمد دادهها در برنامه کمک میکند.
- عبارات شرطی (Conditionals): عبارات شرطی برای کنترل جریان اجرای برنامه استفاده میشوند و مشخص میکنند که برنامه در شرایط مختلف چه عملیاتی را اجرا کند. این ابزار در پیادهسازی منطق تصمیمگیری برنامه نقش کلیدی دارد.
- تبدیل نوع (Typecasting): در برخی موارد، تغییر نوع یک داده ضروری است، مانند تبدیل یک رشته متنی عددی به نوع عددی. این فرآیند از طریق عملیات تبدیل نوع انجام میشود.
- مدیریت خطاها (Exceptions): در حین اجرای برنامه، ممکن است خطاهای غیرمنتظره رخ دهند. به جای توقف کامل برنامه، میتوان این خطاها را شناسایی و مدیریت کرد تا اجرای برنامه بدون وقفه ادامه یابد.
- توابع (Functions): توابع برای تقسیمبندی کد به بخشهای کوچکتر و قابل استفاده مجدد طراحی شدهاند. این رویکرد به سازماندهی بهتر کد و کاهش تکرار در برنامهنویسی کمک میکند.
- ساختارهای داده (List, Tuple, Set, Dictionary): این ابزارها برای ذخیره و مدیریت مجموعههای داده به کار میروند. هر یک از این ساختارها ویژگیها و محدودیتهای خاص خود را دارند و استفاده مناسب از آنها به سازماندهی و مدیریت بهینه دادهها منجر میشود.
برنامهنویسی شیگرا (OOP)
برنامهنویسی شیگرا (Object-Oriented Programming - OOP): یک پارادایم برنامهنویسی است که بر اساس مفهوم "اشیاء" سازماندهی میشود. اشیاء، نمونههایی از کلاسها هستند که دادهها (ویژگیها) و رفتارها (متدها) را در خود ترکیب میکنند. این رویکرد بر چهار اصل اساسی استوار است: کپسولهسازی (Encapsulation) برای محدود کردن دسترسی به دادهها، وراثت (Inheritance) برای استفاده مجدد از کد و ایجاد سلسلهمراتب کلاسها، چندریختی (Polymorphism) برای استفاده از یک رابط مشترک برای اشیاء مختلف، و انتزاع (Abstraction) برای سادهسازی پیچیدگیها با تمرکز بر جزئیات ضروری. برنامهنویسی شیگرا به سازماندهی بهتر کد، افزایش قابلیت استفاده مجدد و تسهیل نگهداری و توسعه نرمافزار کمک میکند.
- کلاسها (Classes): کلاسها الگوهایی هستند که برای ایجاد اشیاء استفاده میشوند. هر کلاس یک نوع خاص از موجودیت را تعریف میکند که شامل ویژگیها (دادهها) و رفتارها (متدها) است. با استفاده از کلاسها میتوان موجودیتهای دنیای واقعی مانند خودرو، کاربر یا محصول را مدلسازی کرد.
- وراثت (Inheritance): وراثت قابلیتی است که امکان ایجاد کلاسی جدید با بهرهگیری از ویژگیها و رفتارهای یک کلاس موجود را فراهم میکند. این مکانیزم به کاهش تکرار کد و بهبود سازماندهی برنامه کمک میکند، زیرا نیازی به تعریف مجدد تمام اجزا از ابتدا نیست.
- متدها (Methods): متدها توابعی هستند که در داخل یک کلاس تعریف میشوند و رفتارهای مربوط به اشیاء آن کلاس را مشخص میکنند. برای مثال، در یک کلاس خودرو، متدی مانند "روشن شدن" میتواند یکی از رفتارهای تعریفشده برای شیء باشد.
- متدهای ویژه (Dunder Methods): متدهای ویژه، که با دو خط زیرین در ابتدا و انتها مشخص میشوند (مانند __init__)، متدهایی هستند که رفتارهای پیشفرض اشیاء را تعیین میکنند. این متدها برای تعریف عملکردهایی مانند ایجاد شیء یا عملیاتهایی مانند جمع بین دو شیء به کار میروند و به حرفهایتر شدن و کنترل بهتر برنامه کمک میکنند.
ساختمان داده و الگوریتمها (DSA) در پایتون
مطالعهی ساختمان داده و الگوریتمها (Data Structures and Algorithms - DSA) برای طراحی و توسعهی برنامههای کارآمد و بهینه ضروری است. این مفاهیم به برنامهنویسان امکان میدهند دادهها را بهصورت مؤثر سازماندهی کرده و عملیات پردازشی را با سرعت و دقت بالا انجام دهند. در این بخش، به بررسی ساختارهای دادهی کلیدی، الگوریتمهای مرتبط و تحلیل کارایی آنها در زبان پایتون پرداخته میشود.
تحلیل پیچیدگی (Time and Space Complexity)
تحلیل پیچیدگی به بررسی میزان منابع موردنیاز یک الگوریتم (زمان اجرا و حافظه) میپردازد. پیچیدگی زمانی و فضایی با استفاده از نماد Big-O توصیف میشود. برای مثال:
- O(1): زمان ثابت، مانند دسترسی به عنصر آرایه.
- O(n): زمان خطی، مانند جستجوی خطی در لیست.
- O(log n): زمان لگاریتمی، مانند جستجوی دودویی. درک این مفاهیم برای انتخاب الگوریتم مناسب در مسائل مختلف حیاتی است.
آرایهها و لیستهای پیوندی (Arrays & Linked Lists)
آرایهها دادهها را در حافظهای پیوسته ذخیره میکنند و دسترسی به عناصر با استفاده از اندیسها سریع است (O(1)). با این حال، افزودن یا حذف عناصر در آرایهها هزینهبر است. لیستهای پیوندی از گرههایی تشکیل شدهاند که هر گره به گرهی بعدی اشاره دارد، و افزودن یا حذف گرهها (O(1)) در آنها سادهتر است، اما دسترسی به عناصر کندتر است (O(n)).
مثال کدنویسی در پایتون:
# پیادهسازی ساده یک گره در لیست پیوندی
class Node:
def __init__(self, data):
self.data = data
self.next = None
کاربرد: آرایهها در ذخیرهسازی دادههای ثابت و لیستهای پیوندی در مدیریت دادههای پویا استفاده میشوند.
پشتهها، صفها و هیپها (Stacks, Queues, Heaps)
این ساختارها برای مدیریت ترتیب ورود و خروج دادهها طراحی شدهاند:
- پشته (Stack): بر اساس اصل "آخرین ورودی، اولین خروجی" (LIFO) عمل میکند. در پایتون، میتوان از لیست یا collections.deque برای پیادهسازی پشته استفاده کرد.
- صف (Queue): بر اساس اصل "اولین ورودی، اولین خروجی" (FIFO) کار میکند. ماژول collections.deque برای صفهای دوطرفه مناسب است.
- هیپ (Heap): ساختاری درختی برای مدیریت دادهها بر اساس اولویت، که در پایتون با ماژول heapq پیادهسازی میشود.
مثال کدنویسی (هیپ):
import heapq
heap = [4, 7, 3]
heapq.heapify(heap) # تبدیل به هیپ
heapq.heappush(heap, 1) # افزودن عنصر
print(heapq.heappop(heap)) # حذف و بازگشت کوچکترین عنصرکاربرد: پشته در مدیریت تاریخچه مرورگر، صف در سیستمهای زمانبندی وظایف، و هیپ در الگوریتمهای اولویتمحور مانند Dijkstra استفاده میشود.
جدولهای هش (Hash Tables)
جدولهای هش دادهها را با استفاده از کلیدهای منحصربهفرد ذخیره و بازیابی میکنند و دسترسی به دادهها در حالت ایدهآل در زمان O(1) انجام میشود. دیکشنریهای پایتون (dict) نمونهای از جدولهای هش هستند.
مثال کدنویسی:
hash_table = {"name": "Ali", "age": 25}
print(hash_table["name"]) # دسترسی سریعکاربرد: در پایگاههای داده و سیستمهای کش برای دسترسی سریع.
درختهای جستجوی دودویی (Binary Search Trees - BST)
درختهای جستجوی دودویی ساختارهایی درختی هستند که هر گره حداکثر دو فرزند دارد و دادهها بهگونهای مرتب میشوند که جستجو، درج و حذف در زمان متوسط O(log n) انجام شود.
مثال کدنویسی:
class Node:
def __init__(self, value):
self.value = value
self.left = None
self.right = Noneکاربرد: در سیستمهای جستجو و پایگاههای داده.
گرافها (Graphs)
گرافها مجموعهای از گرهها (رئوس) و یالها (ارتباطات) هستند که برای مدلسازی روابط استفاده میشوند. گرافها میتوانند جهتدار یا بدون جهت باشند. الگوریتمهای رایج گراف شامل جستجوی عمقاول (DFS) و جستجوی عرضاول (BFS) هستند.
مثال کدنویسی (BFS):
from collections import deque
def bfs(graph, start):
visited = set()
queue = deque([start])
visited.add(start)
while queue:
vertex = queue.popleft()
print(vertex, end=" ")
for neighbor in graph[vertex]:
if neighbor not in visited:
visited.add(neighbor)
queue.append(neighbor)
graph = {0: [1, 2], 1: [0, 3], 2: [0, 3], 3: [1, 2]}
bfs(graph, 0) # خروجی: 0 1 2 3کاربرد: در شبکههای اجتماعی، مسیریابی و تحلیل روابط.
بازگشت (Recursion)
بازگشت تکنیکی است که در آن یک تابع خود را فراخوانی میکند تا مسائل را بهصورت مرحلهای حل کند. این روش در پیمایش ساختارهای درختی و مسائل بازگشتی مانند محاسبه فاکتوریل کاربرد دارد.
مثال کدنویسی:
def factorial(n):
if n <= 1:
return 1
return n * factorial(n - 1)کاربرد: در الگوریتمهای تقسیم و حل و پیمایش درختها.
الگوریتمهای جستجو (Search Algorithms)
- جستجوی خطی (Linear Search): دادهها را به ترتیب بررسی میکند (O(n)).
- جستجوی دودویی (Binary Search): در دادههای مرتب، جستجو را با تقسیم بازه انجام میدهد (O(log n)).
مثال کدنویسی (جستجوی دودویی):
def binary_search(arr, target):
left, right = 0, len(arr) - 1
while left <= right:
mid = (left + right) // 2
if arr[mid] == target:
return mid
elif arr[mid] < target:
left = mid + 1
else:
right = mid - 1
return -1کاربرد: در جستجوی سریع در پایگاههای داده.
الگوریتمهای مرتبسازی (Sorting Algorithms)
الگوریتمهای مرتبسازی دادهها را به ترتیب صعودی یا نزولی سازماندهی میکنند. نمونههای رایج شامل:
- مرتبسازی حبابی (Bubble Sort): O(n²).
- مرتبسازی سریع (Quick Sort): O(n log n) در حالت متوسط.
مثال کدنویسی (Quick Sort):
def quick_sort(arr):
if len(arr) <= 1:
return arr
pivot = arr[len(arr) // 2]
left = [x for x in arr if x < pivot]
middle = [x for x in arr if x == pivot]
right = [x for x in arr if x > pivot]
return quick_sort(left) + middle + quick_sort(right)کاربرد: در پردازش دادهها و آمادهسازی برای جستجو.
برای یادگیری پایتون می توانید از دوره رایگان پایتون در ساینس چین استفاده کنید.
مدیریت پکیجها (Package Managers)
مدیریت پکیجها یکی از جنبههای اساسی توسعه نرمافزار در پایتون است که امکان استفاده از کتابخانههای آماده را فراهم میکند. این ابزارها به توسعهدهندگان اجازه میدهند به جای پیادهسازی کد از ابتدا، از پکیجهای موجود برای تسریع توسعه پروژهها بهره ببرند. در این بخش، ابزارهای کلیدی مدیریت پکیجها و محیطهای کاری در پایتون بررسی میشوند.
مخزن پکیجهای پایتون (PyPI)
Python Package Index (PyPI) یک مخزن آنلاین جامع است که میزبان هزاران کتابخانه و پکیج پایتون برای کاربردهای متنوع نظیر توسعه وب، تحلیل داده، یادگیری ماشین و پردازش تصویر است. توسعهدهندگان میتوانند پکیجهای موردنیاز خود را از این مخزن جستجو و دریافت کنند.
کاربرد: یافتن ابزارهای آماده برای افزودن قابلیتهای پیشرفته به پروژهها.
ابزار pip
pip ابزار رسمی پایتون برای نصب، بهروزرسانی و حذف پکیجها از PyPI است که بهصورت پیشفرض در اکثر نسخههای پایتون موجود است. این ابزار به دلیل سادگی و سرعت، گزینه اصلی توسعهدهندگان برای مدیریت پکیجها محسوب میشود.
دستورات رایج:
pip install numpy # نصب پکیج numpy
pip install numpy==1.21.0 # نصب نسخه خاص
pip list # نمایش پکیجهای نصبشده
pip uninstall numpy # حذف پکیجمشکلات رایج: ناسازگاری نسخهها یا خطاهای شبکه ممکن است هنگام نصب رخ دهند. استفاده از گزینه --no-cache-dir یا بررسی نسخه پایتون میتواند این مسائل را رفع کند.
ابزار conda
conda یک مدیر پکیج و محیط پیشرفته است که بهویژه در پروژههای علمی و دادهمحور کاربرد دارد. برخلاف pip که تنها پکیجهای پایتون را مدیریت میکند، conda قادر به نصب و مدیریت ابزارهای غیرپایتونی (مانند کتابخانههای C) و ایجاد محیطهای کاری مجزا است.
دستورات رایج:
conda install pandas # نصب پکیج pandas
conda create -n myenv python=3.8 # ایجاد محیط جدید
conda activate myenv # فعالسازی محیط
conda env remove -n myenv # حذف محیطکاربرد: مدیریت پروژههای پیچیده با وابستگیهای چندگانه یا نیاز به نسخههای خاص پایتون.
محیطهای مجازی (Virtual Environments)
محیطهای مجازی امکان جداسازی پکیجها و وابستگیهای پروژههای مختلف را فراهم میکنند تا از تداخل آنها جلوگیری شود. ابزارهای اصلی برای ایجاد محیطهای مجازی شامل venv (داخلی در پایتون) و virtualenv هستند.
دستورات رایج با venv:
python -m venv myenv # ایجاد محیط مجازی
source myenv/bin/activate # فعالسازی در لینوکس/مک
myenv\Scripts\activate # فعالسازی در ویندوز
deactivate # غیرفعالسازیکاربرد: استفاده در پروژههایی که نیاز به نسخههای متفاوت پکیجها دارند.
مقایسه pip و conda
- pip: سبک، سریع و مناسب برای پروژههای عمومی. تنها پکیجهای PyPI را مدیریت میکند و معمولاً با محیطهای مجازی استفاده میشود.
- conda: جامعتر، قادر به مدیریت پکیجهای غیرپایتونی و محیطهای کامل. کندتر از pip اما برای پروژههای علمی با وابستگیهای پیچیده مناسبتر است. توصیه: برای پروژههای سبک از pip و venv استفاده کنید؛ برای پروژههای دادهمحور یا چندسکویی، conda گزینه بهتری است.
ابزارهای مدرن (Poetry)
Poetry یک ابزار مدرن برای مدیریت پکیجها و وابستگیها است که فرآیند انتشار پکیج و مدیریت پروژه را سادهتر میکند. این ابزار فایلهای وابستگی (pyproject.toml) را بهصورت خودکار مدیریت کرده و جایگزینی برای pip در پروژههای بزرگ است.
دستور نمونه:
poetry init # ایجاد فایل تنظیمات پروژه
poetry add requests # افزودن پکیجکاربرد: مناسب برای توسعهدهندگانی که به دنبال ابزارهای ساختاریافتهتر هستند.
پیشنهاد مطالعه: آشنایی با اصطلاحات برنامه نویسی
مباحث پیشرفته در پایتون
تسلط بر مفاهیم پیشرفته پایتون به برنامهنویسان امکان میدهد کدهایی بهینه، خوانا و حرفهای تولید کنند. این مفاهیم، که بر پایه دانش اولیه پایتون بنا شدهاند، قابلیتهای قدرتمندی برای توسعه پروژههای پیچیده ارائه میدهند. در این بخش، مفاهیم کلیدی پیشرفته و کاربردهای عملی آنها بررسی میشوند.
ساختارهای فهرستی (List Comprehension)
List Comprehension روشی مختصر برای ایجاد لیستها با استفاده از عبارات فشرده است که جایگزین حلقههای سنتی میشود. این تکنیک خوانایی کد را افزایش داده و عملکرد را بهبود میبخشد.
مثال کدنویسی:
# معادل حلقه: numbers = [x**2 for x in range(5)]
numbers = []
for x in range(5):
numbers.append(x**2)
# با List Comprehension
numbers = [x**2 for x in range(5)] # خروجی: [0, 1, 4, 9, 16]کاربرد: فیلتر کردن دادهها، تبدیل لیستها، و کاهش حجم کد.
مولدها (Generators)
مولدها توابعی هستند که مقادیر را بهصورت تدریجی و یکییکی تولید میکنند، بهجای ذخیره کامل در حافظه. این ویژگی برای پردازش دادههای بزرگ یا جریانهای دادهای مناسب است.
مثال کدنویسی:
def fibonacci(n):
a, b = 0, 1
for _ in range(n):
yield a
a, b = b, a + b
print(list(fibonacci(5))) # خروجی: [0, 1, 1, 2, 3]نکته احتیاطی: استفاده نادرست از مولدها (مانند تکرار چندباره) ممکن است به خطا منجر شود، زیرا مولدها یکبارمصرف هستند.
کاربرد: خواندن فایلهای بزرگ یا پردازش دادههای جریانمحور.
عبارات در پایتون مقادیری هستند که میتوانند در مکانهای مختلف مانند پارامترهای توابع یا شرایط استفاده شوند. عبارات شرطی (مانند x if x > 0 else 0) و عبارات پویا (مانند ساخت توابع در لحظه) انعطافپذیری کد را افزایش میدهند.
مثال کدنویسی:
x = 5
result = x * 2 if x > 0 else 0 # خروجی: 10کاربرد: نوشتن کدهای فشرده و دینامیک در شرایط خاص.
پارادایمهای برنامهنویسی (Programming Paradigms)
پایتون از چندین پارادایم برنامهنویسی پشتیبانی میکند:
- شیگرا (OOP): برای مدلسازی موجودیتها با کلاسها و اشیاء.
- تابعی (Functional): با استفاده از توابع خالص و ابزارهایی مانند map و filter.
- دستوری (Imperative): مبتنی بر دستورات متوالی.
انتخاب پارادایم مناسب به نوع پروژه بستگی دارد.
مثال کدنویسی (تابعی):
numbers = [1, 2, 3]
squared = list(map(lambda x: x**2, numbers)) # خروجی: [1, 4, 9]کاربرد: انطباق با نیازهای پروژههای مختلف.
عبارات منظم ابزاری برای جستجو و پردازش الگوهای متنی هستند که با ماژول re در پایتون پیادهسازی میشوند.
مثال کدنویسی:
import re
text = "Contact: ali@example.com"
emails = re.findall(r'[\w\.-]+@[\w\.-]+', text) # خروجی: ['ali@example.com']نکته احتیاطی: الگوهای پیچیده ممکن است خوانایی کد را کاهش دهند؛ از مستندات دقیق استفاده کنید.
کاربرد: اعتبارسنجی دادهها، استخراج اطلاعات، و پردازش متن.
دکوراتورها (Decorators)
دکوراتورها توابعی هستند که رفتار توابع یا متدهای دیگر را بدون تغییر مستقیم کد آنها اصلاح میکنند.
مثال کدنویسی:
def logger(func):
def wrapper(*args, **kwargs):
print(f"Calling {func.__name__}")
return func(*args, **kwargs)
return wrapper
@logger
def add(a, b):
return a + b
print(add(2, 3)) # خروجی: Calling add \n 5کاربرد: لاگگیری، کنترل دسترسی، و توسعه فریمورکهایی مانند Flask و Django.
تکرارکنندهها (Iterators)
تکرارکنندهها اشیائی هستند که امکان پیمایش مقادیر را بهصورت متوالی فراهم میکنند. پروتکل تکرارکننده در پایتون با متدهای __iter__ و __next__ پیادهسازی میشود.
مثال کدنویسی:
class Counter:
def __init__(self, max):
self.max = max
self.current = 0
def __iter__(self):
return self
def __next__(self):
if self.current < self.max:
self.current += 1
return self.current
raise StopIteration
for num in Counter(3): # خروجی: 1 2 3
print(num)کاربرد: پیمایش ساختارهای داده سفارشی و بهینهسازی حلقهها.
توابع لامبدا (Lambda Functions)
توابع لامبدا توابعی کوتاه و بینام هستند که برای عملیاتهای ساده و موقت استفاده میشوند.
مثال کدنویسی:
sorted_names = sorted(["Ali", "Bob", "Charlie"], key=lambda x: len(x))
print(sorted_names) # خروجی: ['Ali', 'Bob', 'Charlie']نکته احتیاطی: استفاده بیش از حد از لامبدا ممکن است خوانایی کد را کاهش دهد.
کاربرد: ترکیب با توابعی مانند map، filter و sorted.
همزمانی و موازیسازی (Concurrency and Parallelism)
پایتون ابزارهایی برای مدیریت همزمانی و موازیسازی ارائه میدهد:
- threading: برای وظایف ورودی/خروجیمحور (I/O-bound).
- multiprocessing: برای وظایف محاسباتی سنگین (CPU-bound).
- asyncio: برای برنامهنویسی ناهمگام (Asynchronous).
مثال کدنویسی (asyncio):
import asyncio
async def say_hello():
print("Hello")
await asyncio.sleep(1)
print("World")
asyncio.run(say_hello())کاربرد: توسعه برنامههای مقیاسپذیر مانند سرورهای وب یا پردازش دادههای بزرگ.
متاکلاسها برای کنترل ایجاد و رفتار کلاسها استفاده میشوند و در سطح پیشرفته برای سفارشیسازی عمیق به کار میروند.
مثال کدنویسی:
class Meta(type):
def __new__(cls, name, bases, attrs):
attrs['custom_attr'] = 42
return super().__new__(cls, name, bases, attrs)
class MyClass(metaclass=Meta):
pass
print(MyClass.custom_attr) # خروجی: 42کاربرد: توسعه فریمورکها و ابزارهای پیچیده.
بهینهسازی عملکرد
ابزارهایی مانند __slots__ برای کاهش مصرف حافظه، ماژول cProfile برای پروفایلینگ، و کتابخانههای خارجی مانند NumPy برای محاسبات بهینه استفاده میشوند.
مثال کدنویسی (پروفایلینگ):
import cProfile
def slow_function():
return sum(i * i for i in range(1000000))
cProfile.run('slow_function()')کاربرد: بهبود عملکرد برنامههای بزرگ و پیچیده.
پیشنهاد مطالعه: برترین فریم ورک های فرانت اند
فریم ورک های پایتون
برای توسعه برنامههای وب یا رابطهای برنامهنویسی کاربردی (API) در پایتون، استفاده از فریمورکهای وب به جای کدنویسی از ابتدا توصیه میشود. این ابزارها مجموعهای از قابلیتهای آماده را ارائه میدهند که فرآیند توسعه را تسریع کرده، امنیت را بهبود بخشیده و ساختار منسجمی به پروژهها میبخشند.
Django
Django یک فریمورک وب قدرتمند و جامع در پایتون است که برای توسعه سریع و امن برنامههای وب و سیستمهای پیچیده طراحی شده است. این فریمورک با ارائه ابزارهای آماده و ساختار منسجم، فرآیند توسعه را ساده کرده و بهویژه برای پروژههای بزرگ و مقیاسپذیر مناسب است. Django مجموعهای از قابلیتهای داخلی را ارائه میدهد که نیاز به کدنویسی از ابتدا را کاهش میدهند:
- مدیریت پایگاه داده (ORM): یک رابط شیء-رابطهای (Object-Relational Mapping) برای تعامل با پایگاههای داده مانند PostgreSQL، MySQL و SQLite.
- پنل ادمین: رابط کاربری آماده برای مدیریت محتوا و دادهها.
- احراز هویت کاربران: سیستمهای داخلی برای ثبتنام، ورود و مدیریت مجوزها.
- مسیردهی (URL Routing): تعریف الگوهای URL برای هدایت درخواستها به بخشهای مختلف برنامه.
- سیستم قالبها (Template Engine): امکان جداسازی منطق برنامه از رابط کاربری.
- امنیت داخلی: محافظت در برابر حملات رایج مانند تزریق SQL، XSS و CSRF.
معماری Django
Django از الگوی MTV (Model-Template-View) پیروی میکند:
- Model: تعریف ساختار دادهها و تعامل با پایگاه داده از طریق ORM.
- Template: ارائه رابط کاربری با استفاده از سیستم قالبها.
- View: مدیریت منطق برنامه و پردازش درخواستها.
این معماری توسعه را ساختارمند کرده و همکاری بین توسعهدهندگان را تسهیل میکند.
مزایا:
- مناسب برای پروژههای بزرگ و سازمانی به دلیل مقیاسپذیری و ابزارهای جامع.
- مستندات گسترده و جامعه کاربری فعال.
- امنیت بالا و بهروزرسانیهای منظم.
محدودیتها:
- پیچیدگی نسبی برای پروژههای کوچک یا ساده.
- انعطافپذیری کمتر در مقایسه با فریمورکهای سبکتر مانند Flask.
Flask
Flask یک فریمورک وب سبک و انعطافپذیر در پایتون است که برای توسعه برنامههای وب و رابطهای برنامهنویسی کاربردی (API) طراحی شده است. این فریمورک با ارائه ابزارهای اصلی و حداقل، آزادی عمل بالایی به توسعهدهندگان میدهد تا ساختار پروژه را مطابق نیاز خود طراحی کنند. Flask بر سادگی و انعطافپذیری تمرکز دارد و قابلیتهای زیر را ارائه میدهد:
- مسیردهی (URL Routing): تعریف مسیرهای URL برای هدایت درخواستها به توابع مشخص.
- سیستم قالبها (Jinja2): امکان استفاده از قالبهای پویا برای رابط کاربری.
- مدیریت درخواستها: پشتیبانی از درخواستهای HTTP و پردازش دادههای ارسالی.
- افزونههای متنوع (Extensions): امکان افزودن قابلیتهایی مانند احراز هویت، اتصال به پایگاه داده، یا مدیریت فرمها از طریق افزونههایی مانند Flask-SQLAlchemy و Flask-Login.
- هسته سبک: حداقل وابستگیها برای عملکرد سریع و سفارشیسازی آسان.
معماری Flask
Flask از الگوی میکروفریمورک پیروی میکند و برخلاف Django که ساختار مشخصی (MTV) ارائه میدهد، به توسعهدهندگان اجازه میدهد معماری پروژه را آزادانه تعریف کنند. این فریمورک بر پایه کتابخانه WSGI (Werkzeug) برای مدیریت درخواستها و Jinja2 برای قالبها ساخته شده است.
مزایا:
- سبک و سریع، مناسب برای پروژههای کوچک تا متوسط.
- انعطافپذیری بالا در انتخاب ابزارها و ساختار پروژه.
- یادگیری آسان به دلیل سادگی و مستندات قوی.
محدودیتها:
- فقدان ابزارهای آماده (مانند پنل ادمین یا ORM داخلی) در مقایسه با Django.
- نیاز به مدیریت دستی قابلیتهای پیشرفتهتر، که ممکن است برای پروژههای بزرگ زمانبر باشد.
FastAPI
FastAPI یک فریمورک وب مدرن و پرسرعت در پایتون است که برای توسعه رابطهای برنامهنویسی کاربردی (API) طراحی شده است. این فریمورک با بهرهگیری از استانداردهای OpenAPI و ویژگیهای تایپینگ پایتون 3.6 به بالا، فرآیند ساخت APIهای کارآمد و مقیاسپذیر را تسهیل میکند. FastAPI قابلیتهای متعددی را ارائه میدهد که آن را به گزینهای برجسته برای توسعه API تبدیل کرده است:
- پشتیبانی از تایپینگ (Type Hints): استفاده از تایپهای پایتون برای اعتبارسنجی خودکار دادهها و کاهش خطاها.
- مستندسازی خودکار: تولید مستندات تعاملی API با استفاده از Swagger UI و ReDoc بر اساس استاندارد OpenAPI.
- عملکرد بالا: بهرهگیری از برنامهنویسی ناهمگام (Asynchronous) و کتابخانه Starlette برای سرعت قابلمقایسه با فریمورکهای Node.js و Go.
- پشتیبانی از پروتکلهای مدرن: قابلیت کار با WebSocket و GraphQL علاوه بر REST.
- وابستگیهای ساده (Dependency Injection): مدیریت آسان وابستگیها برای بهبود ساختار کد.
معماری FastAPI
FastAPI بر پایه کتابخانه Starlette برای مدیریت درخواستهای ناهمگام و Pydantic برای اعتبارسنجی دادهها ساخته شده است. این فریمورک از الگوی میکروفریمورک پیروی میکند و با تمرکز بر APIها، انعطافپذیری بالایی در طراحی برنامهها ارائه میدهد.
مزایا:
- سرعت بالا و عملکرد بهینه به دلیل پشتیبانی از برنامهنویسی ناهمگام.
- مستندسازی خودکار و کاربرپسند که توسعه و تست API را تسریع میکند.
- مناسب برای میکروسرویسها، یادگیری ماشین، و پروژههای مدرن.
محدودیتها:
- تمرکز اصلی بر APIها، که آن را برای توسعه برنامههای وب کامل (مانند CMS) کمتر مناسب میکند.
- نیاز به دانش برنامهنویسی ناهمگام و تایپینگ برای استفاده بهینه.
Tornado
Tornado یک فریمورک وب سبک و غیرهمزمان (Asynchronous) در پایتون است که برای توسعه برنامههای وب با عملکرد بالا و توانایی مدیریت تعداد زیادی درخواست همزمان طراحی شده است. این فریمورک بهویژه برای سیستمهایی که نیاز به ارتباطات بلادرنگ دارند، مناسب است. Tornado قابلیتهایی را ارائه میدهد که آن را برای برنامههای مقیاسپذیر و بلادرنگ متمایز میکند:
- پشتیبانی غیرهمزمان: استفاده از مدل ورودی/خروجی غیرهمزمان برای مدیریت هزاران اتصال همزمان.
- پشتیبانی از WebSocket: امکان برقراری ارتباطات دوطرفه و بلادرنگ بین سرور و کلاینت.
- مسیردهی (URL Routing): تعریف مسیرهای URL برای هدایت درخواستها به کنترلکنندههای مربوطه.
- سیستم قالبها: ارائه ابزارهای ساده برای رندر قالبهای پویا.
- سبک و مستقل: حداقل وابستگیها برای عملکرد سریع و سفارشیسازی آسان.
معماری Tornado
Tornado بر پایه مدل غیرهمزمان و حلقه رویداد (Event Loop) ساخته شده است که امکان پردازش کارآمد درخواستها را فراهم میکند. این فریمورک از معماری میکروفریمورک پیروی کرده و بر عملکرد و سادگی تمرکز دارد، که آن را از فریمورکهای جامعتر مانند Django متمایز میکند.
مزایا:
- عملکرد بالا در مدیریت درخواستهای همزمان، مناسب برای برنامههای بلادرنگ مانند چت آنلاین.
- سبک و انعطافپذیر، با امکان سفارشیسازی بالا.
- پشتیبانی قوی از WebSocket برای ارتباطات دوطرفه.
محدودیتها:
- فقدان ابزارهای آماده (مانند ORM یا پنل ادمین) در مقایسه با فریمورکهای جامعتر.
- نیاز به دانش برنامهنویسی غیرهمزمان برای استفاده بهینه.
پیشنهاد مطالعه: معرفی 5 فریمورک برتر بلاک چین
اتوماسیون و تستنویسی با پایتون
پایتون به دلیل انعطافپذیری و کتابخانههای قدرتمند، ابزاری کارآمد برای خودکارسازی وظایف تکراری و زمانبر است. این قابلیت امکان صرفهجویی در زمان و اجرای وظایف بدون نیاز به دخالت دستی را فراهم میکند. علاوه بر این، پایتون در تستنویسی نرمافزار نقش مهمی ایفا میکند و به توسعه کدهای قابل اطمینان و باکیفیت کمک میکند.
کار با فایلها
مدیریت فایلها یکی از جنبههای کلیدی اتوماسیون در پایتون است که شامل خواندن، نوشتن، ویرایش، جابهجایی یا حذف فایلهایی مانند متنی، CSV، PDF و سایر فرمتها میشود.
- خواندن و نوشتن: استخراج دادهها از فایلها یا ایجاد گزارشهای جدید.
- مدیریت ساختار فایلها: سازماندهی، کپی یا حذف فایلها در سیستم.
- پشتیبانی از فرمتها: تعامل با فایلهای پیچیده مانند PDF با استفاده از کتابخانههایی نظیر PyPDF2.
کاربرد: پردازش دادهها، تهیه گزارشهای خودکار، و پشتیبانگیری از اطلاعات.
استخراج اطلاعات از وب (Web Scraping)
استخراج اطلاعات از وب فرآیندی است که طی آن دادهها بهصورت خودکار از وبسایتها جمعآوری میشوند. این کار با استفاده از کتابخانههایی مانند BeautifulSoup برای پارس HTML یا Selenium برای شبیهسازی تعاملات مرورگر انجام میشود.
- جمعآوری دادهها: استخراج اطلاعاتی مانند قیمت محصولات، اخبار، یا اطلاعات تماس.
- پیمایش پویا: مدیریت صفحات وب با محتوای دینامیک یا جاوااسکریپت.
کاربرد: تحلیل بازار، جمعآوری دادههای پژوهشی، و استخراج اطلاعات تجاری.
اتوماسیون رابط کاربری (GUI Automation)
اتوماسیون رابط کاربری امکان شبیهسازی تعاملات انسانی با نرمافزارها را فراهم میکند. این فرآیند با کتابخانههایی مانند PyAutoGUI یا Selenium انجام میشود.
- شبیهسازی ورودیها: اجرای کلیکها، تایپ، یا پر کردن فرمها.
- تعامل با برنامهها: کنترل نرمافزارهایی مانند اکسل، مرورگرها، یا ابزارهای دسکتاپ.
کاربرد: تست رابط کاربری، خودکارسازی وظایف اداری، و مدیریت گردش کار.
اتوماسیون شبکه
پایتون قابلیت تعامل با ابزارها و دستگاههای شبکه را از طریق کتابخانههایی مانند paramiko، smtplib، یا requests فراهم میکند.
- مدیریت دستگاهها: پیکربندی خودکار روترها و سوئیچها.
- ارتباطات شبکهای: ارسال ایمیل یا تعامل با APIهای وب.
کاربرد: مدیریت زیرساختهای شبکه، خودکارسازی وظایف DevOps، و نظارت بر سیستمها.
تستنویسی (Testing)
تستنویسی فرآیندی ضروری در توسعه نرمافزار است که صحت عملکرد کد را تضمین کرده و از بروز خطاها در تغییرات بعدی جلوگیری میکند. پایتون با ابزارهایی مانند unittest، pytest و nose امکانات گستردهای برای تستنویسی ارائه میدهد.
- افزایش اطمینان: تضمین عملکرد صحیح کد در شرایط مختلف.
- کاهش خطاها: شناسایی مشکلات پیش از استقرار برنامه.
- نگهداری آسانتر: تسهیل اصلاحات و بهروزرسانیهای پروژه.
تست واحد (Unit Testing)
تست واحد بر بررسی عملکرد مستقل بخشهای کوچک برنامه، مانند توابع یا متدها، تمرکز دارد. این روش با کتابخانههایی مانند unittest یا pytest پیادهسازی میشود.
- تست مستقل: ارزیابی هر جزء بدون وابستگی به سایر بخشها.
- تشخیص سریع خطاها: شناسایی تغییرات غیرمنتظره در عملکرد کد.
کاربرد: تضمین کیفیت توابع و ماژولهای جداگانه.
تست یکپارچه (Integration Testing)
تست یکپارچه تعامل بین اجزای مختلف سیستم را بررسی میکند تا از هماهنگی صحیح آنها اطمینان حاصل شود.
- ارزیابی تعاملات: بررسی ارتباط بین ماژولها، مانند فرمها و پایگاه داده.
- شناسایی مشکلات یکپارچگی: تشخیص خطاها در نقاط اتصال سیستم.
کاربرد: اعتبارسنجی عملکرد کلی بخشهای ترکی.ی.
تست سرتاسری (End-to-End Testing)
تست سرتاسری کل سیستم را از دیدگاه کاربر نهایی شبیهسازی و بررسی میکند.
- شبیهسازی رفتار کاربر: ارزیابی فرآیندهای کامل مانند ثبتنام یا پرداخت.
- تضمین تجربه کاربری: اطمینان از عملکرد صحیح سیستم در سناریوهای واقعی.
کاربرد: اعتبارسنجی عملکرد کلی برنامه در محیطهای عملیاتی.
توسعه مبتنی بر تست (Test-Driven Development - TDD)
TDD یک روش برنامهنویسی است که در آن ابتدا تستها نوشته شده و سپس کدی توسعه مییابد که این تستها را با موفقیت پشت سر بگذارد.
- طراحی بهتر کد: تولید کدهای تمیزتر و ساختارمندتر.
- اعتمادپذیری بالا: کاهش احتمال بروز خطاها در توسعه.
کاربرد: توسعه نرمافزارهای قابل اطمینان و قابل نگهداری.
پیشنهاد ویژه: برای سفارش طراحی سایت اختصاصی با بهترین زبان های برنامه نویسی، کلیک کنید.
علم داده (Data Science)
علم داده رشتهای است که از پایتون برای تحلیل دادهها، شناسایی الگوها، پیشبینی روندها و پشتیبانی از تصمیمگیریهای مبتنی بر داده استفاده میکند. پایتون به دلیل کتابخانههای متنوع و قدرتمند، به ابزاری پیشرو در این حوزه تبدیل شده است.
- NumPy کتابخانهای برای انجام محاسبات عددی و مدیریت آرایههای چندبعدی است که عملیات ریاضی و برداری را با سرعت بالا اجرا میکند.
- Pandas ابزاری برای پردازش و تحلیل دادههای جدولی است که امکان فیلتر، گروهبندی، پاکسازی و خلاصهسازی دادهها را فراهم میکند.
Matplotlib کتابخانهای برای بصریسازی دادهها است که امکان ایجاد نمودارهای متنوع مانند خطی، میلهای و پراکندگی را ارائه میدهد.
Seaborn کتابخانهای مبتنی بر Matplotlib است که برای رسم نمودارهای آماری پیشرفته با رابط کاربری ساده و ظاهر جذاب طراحی شده است.
Scikit-learn کتابخانهای برای یادگیری ماشین است که ابزارهایی برای اجرای الگوریتمهای طبقهبندی، خوشهبندی و رگرسیون ارائه میدهد.
TensorFlow کتابخانهای برای یادگیری عمیق است که برای ساخت و آموزش شبکههای عصبی پیچیده در کاربردهای هوش مصنوعی استفاده میشود.
PyTorch کتابخانهای برای یادگیری عمیق است که به دلیل انعطافپذیری و سهولت در دیباگینگ، برای تحقیقات و آزمایشهای علمی مناسب است.
مریم گوهرزاد
مدرس و بنیانگذار هلدینگ آرتا رسانه. برنامه نویس و محقق حوزه بلاکچین



