
واحدهای بازگشتی دروازهای GRU
 توسط مریم گوهرزاد
توسط مریم گوهرزاد- هوش مصنوعی
- آوریل 27, 2025
- 1 دقیقه زمان خواندن
- 780 بازدید
واحد بازگشتی دروازهای (GRU) یک نوع شبکه عصبی بازگشتی است که برای پردازش دادههای دنبالهای بهینهسازی شده است. این الگوریتم با استفاده از دو گیت فراموشی و آپدیت قادر است اطلاعات بلندمدت را بهخوبی حفظ کند. GRU نسبت به LSTM سادهتر و سریعتر است و در کاربردهایی مانند پیشبینی سریهای زمانی، پردازش زبان طبیعی و تشخیص گفتار بسیار مفید است.
در عصر اطلاعات و پیشرفتهای سریع در حوزه هوش مصنوعی، پردازش دادههای دنبالهای به یکی از چالشهای کلیدی تبدیل شده است. الگوریتم GRU (Gated Recurrent Unit) بهعنوان یک نوع شبکه عصبی بازگشتی (RNN) بهمنظور بهبود عملکرد در این زمینه معرفی شده است. GRU با هدف کاهش پیچیدگی و افزایش کارایی، قابلیت یادآوری اطلاعات را در طول زمانهای طولانی بهبود میبخشد و بهطور مؤثری مشکلاتی نظیر محو شدن گرادیان را که در شبکههای عصبی سنتی مشاهده میشود، حل میکند.
این الگوریتم با استفاده از ساختار دروازهای خاص خود، به شبکه اجازه میدهد تا بهطور دینامیک اطلاعات را بهروز رسانی کرده و تصمیمات بهتری را در پردازش دنبالههای زمانی اتخاذ کند. در این مقاله، به بررسی ساختار، ویژگیها و کاربردهای GRU خواهیم پرداخت و تأثیر آن را در پیشرفتهای اخیر در حوزههای مختلف هوش مصنوعی، از جمله پردازش زبان طبیعی و شناسایی گفتار، تحلیل خواهیم کرد. هدف ما این است که نشان دهیم چگونه GRU میتواند به عنوان یک ابزار مؤثر در بهبود دقت و سرعت الگوریتمهای یادگیری ماشین عمل کند.
پیشنهاد مطالعه: شبکه عصبی حافظه طولانی کوتاه مدت چیست؟
Table of contents [Show]
معرفی واحدهای بازگشتی دروازهای GRU
واحد بازگشتی دروازهای (Gated Recurrent Unit یا GRU) یک نوع شبکه عصبی بازگشتی است که برای پردازش دادههای دنبالهای طراحی شده است. GRU با هدف سادهسازی ساختار LSTM (Long Short-Term Memory) و افزایش کارایی، بهویژه در وظایف یادگیری عمیق، توسعه یافته است. این شبکه از دو دروازه اصلی استفاده میکند که به آن اجازه میدهد تا اطلاعات را بهطور مؤثر مدیریت کند و در عین حال از محو شدن گرادیان جلوگیری کند.
ساختار داخلی GRU
GRU شامل دو گیت اصلی است که باعث بهبود عملکرد آن نسبت به مدلهای RNN سنتی میشود:
گیت فراموشی (Reset Gate)
گیت فراموشی به مدل کمک میکند که مشخص کند چه مقدار از وضعیت قبلی باید فراموش شود و چه مقدار باید در وضعیت فعلی لحاظ شود. در واقع، این گیت تصمیم میگیرد که اطلاعاتی که به مدل وارد میشود چقدر باید از وضعیت قبلی تاثیر بگیرد.
گیت آپدیت (Update Gate)
گیت آپدیت مسئول این است که چه مقدار از وضعیت قبلی باید در وضعیت فعلی حفظ شود. در واقع، این گیت برای یادگیری روابط بلندمدت در دادهها استفاده میشود و مقدار اطلاعات قبلی را با ورودی جدید ترکیب میکند.
عملکرد واحد بازگشتی دروازهای
در هر گام زمانی، GRU با استفاده از این دو گیت تصمیم میگیرد که:
- چه مقدار از وضعیت قبلی باید فراموش شود (گیت فراموشی).
- چه مقدار از وضعیت قبلی باید به وضعیت جدید منتقل شود (گیت آپدیت).
به طور خلاصه، گیت فراموشی و آپدیت به مدل کمک میکنند تا اطلاعات مهم را از دنبالههای زمانی طولانیتر بهخوبی حفظ کند و از فراموشی اطلاعات جلوگیری کند.
فرمولهای ریاضی GRU
برای هر گام زمانی ttt ، وضعیت مخفی hth_tht به این صورت محاسبه میشود:
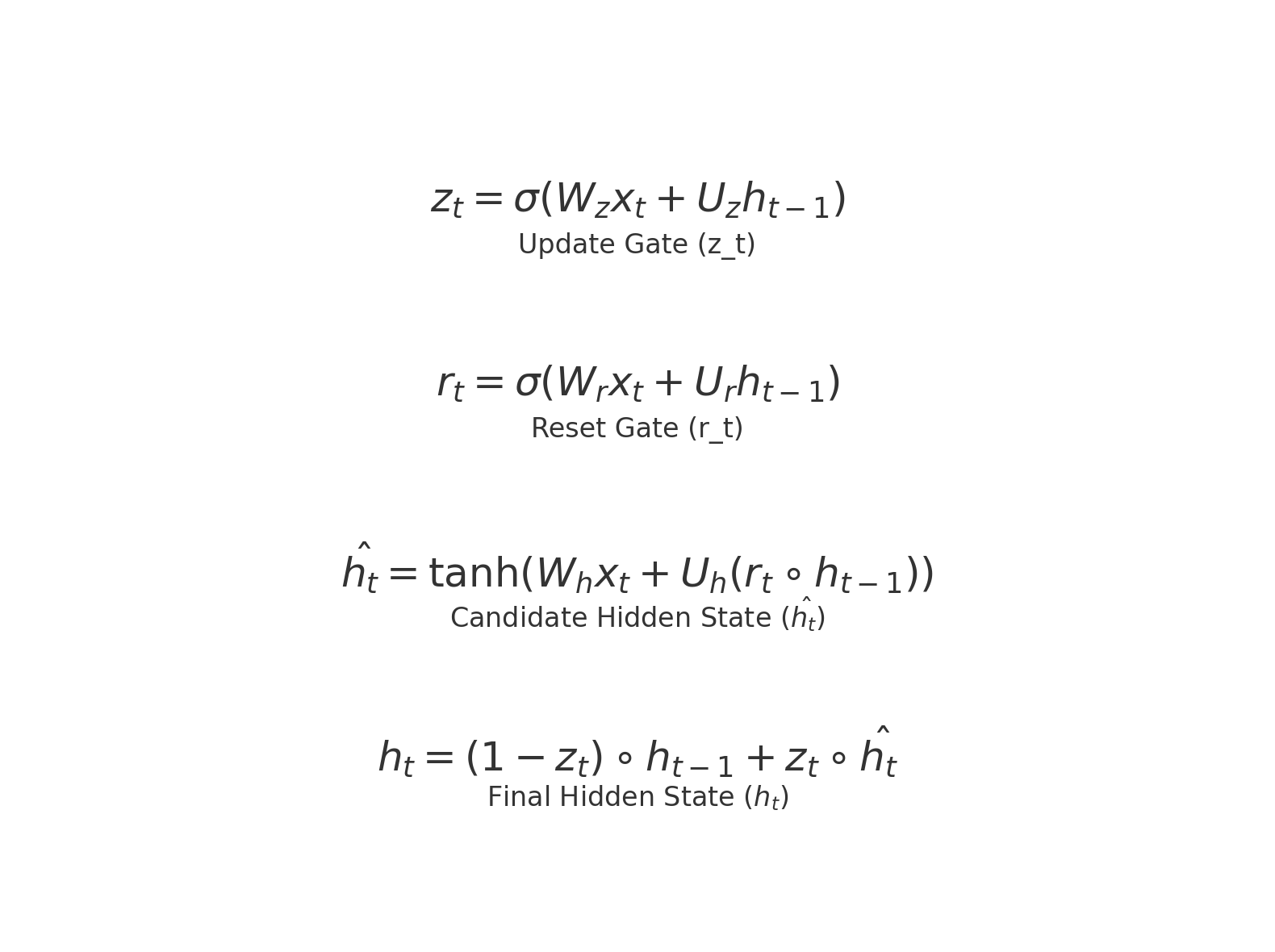
گیت آپدیت:
که در آن:
- ztz_tzt : گیت آپدیت
- σ\sigmaσ : تابع سیگموید
- WzW_zWz و UzU_zUz : وزنها
- xtx_txt : ورودی در گام زمانی ttt
- ht−1h_{t-1}ht−1 : وضعیت قبلی
گیت فراموشی:
rt=σ(Wrxt+Urht−1)r_t = \sigma(W_r x_t + U_r h_{t-1})rt=σ(Wrxt+Urht−1)
که در آن:
- rtr_trt : گیت فراموشی
- WrW_rWr و UrU_rUr : وزنها
محاسبه وضعیت جدید:
که در آن:
- ht^\hat{h_t}ht^ : وضعیت کاندید جدید (محتویات جدیدی که به وضعیت فعلی اضافه میشود)
- ∘\circ∘ : ضرب عنصر به عنصر
وضعیت مخفی نهایی:
که در آن:
- hth_tht : وضعیت مخفی نهایی که ترکیبی از وضعیت قبلی و وضعیت جدید است.
پیشنهاد مطالعه: الگوریتم یادگیری تقویتی چیست؟
مزایای GRU نسبت به LSTM
GRU نسبت به LSTM سادهتر است و عملکرد مشابهی در بسیاری از وظایف دارد. از مزایای آن میتوان به موارد زیر اشاره کرد:
- سادهتر بودن: GRU فقط از دو گیت استفاده میکند، در حالی که LSTM از سه گیت استفاده میکند. این سادگی باعث میشود که GRU نسبت به LSTM کارایی بیشتری در پردازشهای سریع و بهینه داشته باشد.
- میزان کمتر پارامترها: به دلیل سادهتر بودن ساختار، تعداد پارامترهای GRU نسبت به LSTM کمتر است.
- عملکرد مشابه: در بسیاری از کاربردها، GRU عملکرد مشابه با LSTM دارد و حتی در برخی از آنها بهتر عمل میکند.
مقایسه با RNN و LSTM
- RNN ساده: در RNNهای ساده، فقط یک گیت برای انتقال اطلاعات از گامهای قبلی به گامهای فعلی وجود دارد. این میتواند باعث از دست رفتن اطلاعات در دنبالههای طولانی شود.
- LSTM: LSTM از سه گیت برای ذخیره و فراموش کردن اطلاعات استفاده میکند و میتواند یادگیری بلندمدت بهتری داشته باشد.
- GRU: GRU با استفاده از دو گیت (گیت فراموشی و گیت آپدیت)، سادگی بیشتری نسبت به LSTM دارد ولی همچنان توانایی یادگیری روابط بلندمدت را بهخوبی حفظ میکند.
کاربرد واحد بازگشتی دروازهای
GRU در بسیاری از کاربردها به خصوص در پردازش دادههای دنبالهای مانند موارد زیر استفاده میشود:
- پیشبینی سریهای زمانی: مثل پیشبینی قیمت ارز دیجیتال یا پیشبینیهای مالی.
- پردازش زبان طبیعی (NLP): در کارهایی مثل ترجمه ماشینی، تولید متن و تحلیل احساسات.
- تشخیص صدا و گفتار: در کاربردهایی مثل شناسایی کلمات و جملات در دادههای صوتی.
نتیجهگیری:
GRU یک نوع بهینهشده از RNN است که با استفاده از دو گیت (گیت فراموشی و گیت آپدیت) توانایی حفظ اطلاعات بلندمدت را دارد و نسبت به LSTM سادهتر و سریعتر است. این ویژگیها باعث میشود که GRU در بسیاری از کاربردهای یادگیری عمیق مانند پردازش زبان طبیعی و پیشبینی سریهای زمانی بسیار مفید باشد.
مریم گوهرزاد
مدرس و بنیانگذار هلدینگ آرتا رسانه. برنامه نویس و محقق حوزه بلاکچین



